The first premise to understand is that simple harmonic motion through time generates sinusoidal motion.
The following diagram will display the amplitude of the harmonic motion and for this we need to use the term A in our formula. We will also be using θ.
I have used the equation A sin θ where θ completes one cycle (degrees). The y axis displays values based on a unit circle with A being interpreted as amplitude. The x axis denotes degrees (θ)
It then follows that:
When the angle θ is 0° or 180° then y = 0 sin 0° and sin 180° = y/A = 0
When the angle θ is 90° then y = 1 sin 90° = y/A = 1
When the angle θ is 270° then y = −1 sin 270° = y/A = −1
When constructing and working with sinusoids we need to plot our graph and define the axis.
I have chosen the y-axis for amplitude and the x-axis for time with phase expressed in degrees. However, I will later define the formulae that define the variables when we come to expressing the processes.
For now, a simple sine waveform, using each axis and defining them, will be enough.
I will create the y-axis as amplitude with a range that is set from -1 to +1. y: amplitude
Now to create the x-axis and define its variables to display across the axis.
The range will be from -90 deg to 360 deg x: time/phase/deg
The following diagram displays the axis plus the waveform and the simplest formula to create a sinusoid is y-sinx
The diagram shows one cycle of the waveform starting at 0, peaking at +1 (positive), dropping to the 0 axis and then down to -1 (negative).
The phase values are expressed in degrees and lie on the x-axis. A cycle, sometimes referred to as a period, of a sine wave is a total motion across all the phase values.
I will now copy the same sine wave and phase offset (phase shift and phase angle) so you can see the phase values and to do this we need another simple formula and that is: y=sin(x-t) where t (time/phase value) being a constant will, for now, have a value set to 0. This allows me to shift by any number of degrees to display the phase relationships between the two sine waves.
The shift value is set at 90 which denotes a phase shift of 90 degrees. In essence, the two waveforms are now 90 degrees out of phase.
The next step is to phase shift by 180 deg and this will result in total phase cancelation. The two waveforms together, when played and summed, will produce silence as each peak cancels out each trough.
So, what is Panning Law and does anyone really care?
Hell yeah!
In fact, I can state that many producers/engineers that I meet have little or no clue about the panning law. As far as they are concerned, you turn the knob and the sound moves from one side of the stereo field to the other.
What is not understood is that certain things happen to the sound when it is panned from one side of the field, through the centre, and then to the other side of the field.
When you are dealing with monaural sounds you have to take into account the dynamics of the sound when it is moved and summed. This is very important when it comes to the mix stage as many people seem to complain about how the sound behaves when it is panned, to the point that most software developers have tried to accommodate for the panning law in their coding.
The problem facing most newcomers to this industry is that once a project is mixed in certain software and the project is then imported in separate mix software, the panned levels go for walkies. This is down to how the software behave and process the panning law, compensating for the characteristics of the process.
When a signal is panned centrally, the same signal will be output (identically) on both the left and right channels. If you were to pan this signal from the extreme left channel through the centre and then onto the extreme right channel, it will sound as if the level rises as it passes through the centre. The panning law was integrated to introduce a 3dB level drop at the centre. If you were to sum the left and right channels in a mono situation, the centre gain would result in a 6dB rise, so attenuating by that amount became a must in the broadcast industry as mono compatibility is always a prime issue.
So, what the hell is the panning law?
The panning law determines the relationship between the sound’s apparent image position and the pan knob control. This refers to the way the sound behaves when it is moved across the stereo field. The usual requirement is that it moves smoothly and linearly across the field. This is, of course, pertinent to log/anti-log laws. If there was a linear gain increase in one channel and a linear gain decrease in the other channel to change the stereo position, at the centre position the sum of the two channels sounded louder than if the signal was panned full left or full right. Why do you think we had to attenuate the gain whenever we panned a sound central?
Digital consoles and the digital domain started to change this thinking and accommodate and compensate for this behaviour.
It became necessary to attenuate the centre level by four common centre attenuation figures: 0, -3. -4.5 and -6dB. The -3dB figure is the most natural because it ensures that the total acoustic power output the studio monitors remains subjectively constant as the source is panned from one extreme of the stereo field to the other. However, it also produces a 3dB bulge in level for central sources if the stereo output is summed to mono, and that can cause a problem for peak level metering for mono signals. So, most broadcast desks employ a -6dB centre attenuation so that the derived mono signal is never louder than either channel of the stereo source. However, sounds panned centrally may end up sounding a little quieter than when they are panned to the edges.
Confusing huh?
Well, the answer is to simply compromise and split the difference and this is what led to most modern analogue consoles working off a -4.5dB centre attenuation.
So, what does this mean to you and how does it help you, particularly if you are working ITB (in the box) and with different software? The answer is quite simple: find out what the software panning preferences are and adjust to taste. Most of today’s software will allow for fine-tuning the panning law preferences. Cubase, along with most of the big players, has a preference dialogue box for exactly this. Cubase defaults to -3dB (classic equal power), but has settings for all the standards and I tend to work off -4.5dB.
If you stay with the old school days of 0dB, then you are in ‘loud centre channel land’, and a little bit of gain riding will have to come into play.
Check your software project and make sure you set the right preference, depending on what the project entails in terms of the mix criteria.
If you would prefer a visual explanation then try this video tutorial:
https://samplecraze.com/wp-content/uploads/2019/01/levelPan.gif10221438eddiehttps://samplecraze.com/wp-content/uploads/2019/09/samplecraze-logo-red.pngeddie2019-01-02 12:55:092020-01-30 15:18:31The Pan Law
Does what it says on the tin. By adding one or more basic and simple waveforms together and their harmonics you create a complex waveform. However, you need to add an enormous amount of harmonics to create the simplest of sounds and this type of synthesis can be complicated to create in the form of a synthesizer but the Kawai K5000 does exactly that. You can create extremely rich textures or wild and crazy sounds on this beast. Personally, I love additive synthesis but then again I am receiving very intense therapy. The process of additive synthesis is also referred to as summing the waveforms and harmonics. This method adopts Fourier analysis. Described as the representation of a sound’s frequency components as a sum of pure sinusoidal waves. An analysis of a sound’s frequency components is taken at a steady state to give an approximation of that sounds spectrum. As most natural sounds are spectrally dynamic, one single Fourier analysis could not possibly represent a sound in sine waves. By ‘windowing’, a Fast Fourier Transform (FFT) takes several of these approximations and strings them together to better predict a sound’s spectrum over time. Although this is daunting to take in it is crucial to know and I don’t expect you to understand Fourier analysis but just thought I would bring it in now as we will come back to this at the advanced stages of these tutorials.
SUBTRACTIVE
This process involves the generating of complex waveforms and then filtering the frequencies so that you are then left with the sound you want. You take away the frequencies. Obviously the filters are crucial in subtractive synthesis and the better the filters and the wider the choice of filters available, the better the end result will be. When I teach students I find Subtractive Synthesis to be the easiest and most logical introduction to sound design.
FREQUENCY MODULATION (FM)
The output of one oscillator (modulator) is used to modulate the frequency of another oscillator (carrier). These oscillators are called operators. FM synthesizers usually have 4 or 6 operators. Algorithms are predetermined combinations of routings of modulators and carriers. To really explain this I would have to go into harmonics, sidebands, non-coincident and coincident series and the relationships between modulators and carriers. So I won’t go there. What I will say is that FM synthesis can create lovely digital types of sounds, from brittle to lush. A little bit of info for DX owners, is that the oscillators on these synthesizers were all sine waves.
PHYSICAL MODELLING (PM or PHM)
This form of synthesis simulates the physical properties of natural instruments, or any sound, by using complex mathematical equations in real-time. This requires huge processing power. You are not actually creating the sound but, you are creating and controlling the process that produces that sound. Waveguides and algorithms come into this process heavily but, again, I won’t go into that as it would complicate issues and confuse you. What I do find interesting is that the Nord Lead uses PM synthesis to emulate an analog synthesizer. Weird huh?
LINEAR ARITHMETIC SYNTHESIS
This type of synthesis takes short attack sampled waveforms called PCM, or Pulse Code Modulation and combines them with synthesized sounds that form the body and tail of the new sound. By layering these and combining them with the synthesized portion of the sound you arrive at the new sound. The final sound is processed by using filters, envelope generators etc. This is one of the most common forms of synthesis used in the 90s and even today. Roland was the most famous for adopting this type of synthesis and the D50 was one of the most common of the synthesizers that used LA synthesis. By the way, a great synthesizer and still used today.
WAVETABLE SYNTHESIS
This form of synthesis incorporates the use of pre-recorded digitized audio waveforms of real or synthetic instruments. The waveforms are then stored in memory and played back at varying speeds for the corresponding notes played. These waveforms usually have a looped segment which allows for a sustained note to be played. Using envelopes and modulators, these waveforms can be processed and layered to form complex sounds that can often be lush and interesting. The processes are algorithmic and memory is crucial to house the waveforms. I could get into linear crossfading sequentially, quasi-periodic and sine functions etc. But I won’t. I care about your sanity.
GRANULAR SYNTHESIS
This is the method by which tiny events of sounds (grains or clouds) are manipulated to form new complex sounds. By using varying frequencies and amplitudes of the sonic components, and by processing varying sequences and durations of these grains, a new complex sound is formed. Simply put, this form of synthesis creates some crazy and interesting sounds.
ADVANCED VECTOR SYNTHESIS ( AVS )
This method of synthesis incorporates the combining and processing of digital waveforms. Using PCM samples, effects and filtering this method of synthesis can create stunning sounds, from lush and evolving pads to strange stepped sequences. Korg made the famous Wavestation range of synthesizers and these were based around the Sequential Circuits Prophet VS. Working off a 2-dimensional envelope using an X and Y axis (joystick) and 4 voices, this synthesizer also had wave sequencing, playing a loopable sequence of PCM samples in a rhythmic and/or crossfaded fashion. The idea was to be able to crossfade 2 or more waveforms using the joystick. Freaky but incredible.
Synthesizers used to be categorized into 2 categories, analog and digital, but in the modern world, we have the hybrid digital-analog synthesizer. Confused? Don’t be. It actually makes good sense. Whether the processing is digital or analog, the sounds are produced in much the same way, albeit with different terminology and some different routings. A good example of the terminology being adapted is: VCO, voltage controlled oscillator becomes a DCO, digitally controlled oscillator.
Of course, with today’s influx of synthesizers, be they analog, digital or a hybrid system, we are offered many varying forms of synthesis, from granular to transwave and so on.
Ultimately, synthesis is about sound design and manipulation and we now have fully fledged systems whereby effects are incorporated into the signal matrix, dynamics at the output stage and modulation matrices that make modular synthesizers look primitive. But would I swap a modular synth for a hybrid plugin? Hell no!
https://samplecraze.com/wp-content/uploads/2019/01/moog-mother-32-rack-thefuturefm-djs.jpeg764800eddiehttps://samplecraze.com/wp-content/uploads/2019/09/samplecraze-logo-red.pngeddie2019-01-02 10:37:202020-01-30 15:20:55Synthesis and Sound Design – Various Types
As with all my existing and future reviews, I will only be reviewing what I use and in practice and I will keep all reviews as working reviews and not an epic encyclopedia of opinions. I will leave that to the magazines and e-zine sites.
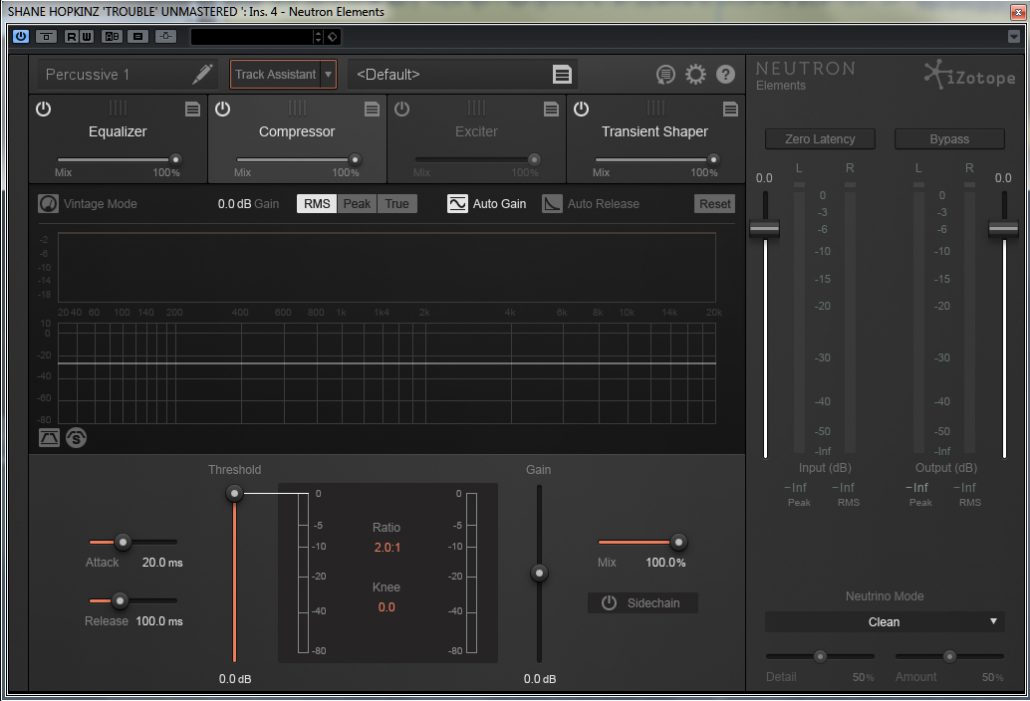
This month I am going to go on and on and on about iZotope’s Neutron Elements, a wonderful all in one solution to all things that need clever algorithmic analysis and processing.
The key features of Neutron Elements are:
Track Assistant – iZotope’s clever analyse and compensatory tool.
Track identification – Neutron Elements identifies the type of ‘instrument’ being used and applies compensatory profiles at a click.
EQ Learn – Neutron Elements listens to the incoming audio and applies, yet again, clever compensation.
Four powerful single band processors: EQ, Compressor, Exciter and Transient Shaper – a modular approach to processing.
Over 200 presets for you to start from or use as is.
Linear and Minimum Phase topologies that help to further shape your sounds.
Mode selection tools based on the type of instrument and sound.
Choice of interesting Responses for EQs.
Fully Configurable.
Fully automated.
Neutron Elements (NE) is a honed down version of iZotope’s Neutron but is still an extremely powerful tool offering the user countless configurations of dynamic tools. Brimming with instrument-specific presets Neutron Elements presents the user with excellent starting templates to hone and edit to taste. Neutron Elements follows the channel-strip concept and features four modules and Track Assistant on top! But beneath the simple GUI lies a wealth of quality processors.
The beauty of the modular approach is that the order of dynamics can be changed by grabbing any module and moving it before or after another module. This means you are not restricted to using a fixed modular approach. Eq before compression? Sure, why not? Eq after compression? Sure, why not? The ability to chop and change the order of dynamics is as potent as the processors provided.
Track Assistant
Track Assistant is an interesting tool and can be compared to all analysis and compensatory processes in that it will analyse the incoming audio and make working suggestions as to how to sonically improve the results. This is not new technology and has been in use by many companies for many years. In fact, I would go as far as saying that HarBal reigns supreme here and not only is it a better mastering and processing tool it is also far more intuitive than Neutron. Whereas Neutron Elements suggests a single solution to each profile HarBal goes further and offers a combination of suggestions all based on simple physics as opposed to subjective opinions of producers and their preset profiles. That is not to say Neutron Elements does not offer powerful ‘suggestive’ options as to what to use and how to use it. You could, in effect, just use Track Assistant and be done with your audio….but I suggest you go a little further and switch off this feature and work with the truly wonderful features that reside in this powerful software.
When dealing with audio we are invariably concerned with cleaning, shaping, and dynamic control. NE provides all the necessary tools to achieve these goals. An equaliser sits in the prime spot, and rightly so, as we need to bandpass and clean redundant frequencies at both the channel and master bus stages. However, if you don’t fancy an eq at the start of the chain, it is as easy as clicking on the module and dragging it where you do want it to sit. In the event that you only want to filter and not clean then NE gives us the very useful Vintage response, in addition to the existing Shelf and Baxandall modes (there are times when pre-ringing is exactly what we want). The eq bands are not fixed and all have Q controls. Additionally, iZotope have thrown in a Learn function. This, when selected, will analyse the incoming audio and suggest where the frequency nodes should sit. After that, it is just a matter of cut and boost. Clever and useful.
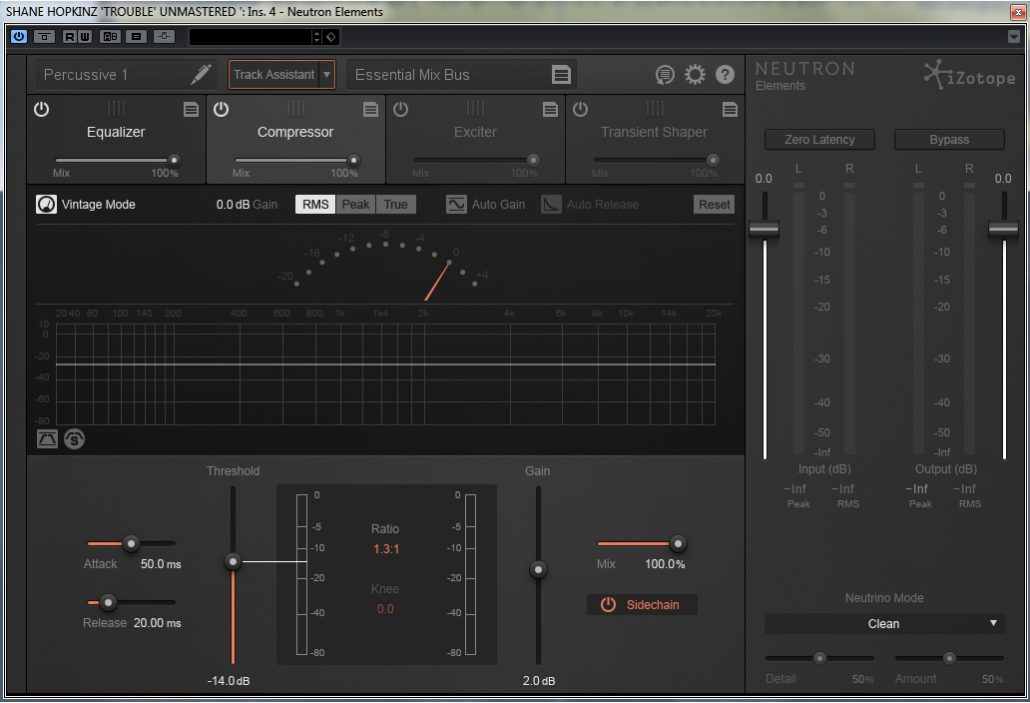
Compressor
Next up, we have a very useful compressor that can be used in parallel mode and is as easy to use as possible. The compressor works using two Modes: Digital and Vintage. Think of Digital as uncoloured and Vintage as coloured.
Level Detection Mode
These three buttons, RMS, Peak, and True, allow you to adjust which level detection mode the Compressor uses, as follows:
Peak enables Neutron’s detection circuit to look at peak levels of the incoming signal. In general, this setting is useful when you are trying to even out sudden transients in your music.
RMS enables Neutron to look at the average level of the incoming signal. RMS detection is useful when you are trying to increase the overall volume level without changing the character of the sound.
True mode behaves much like RMS mode, but with some key advantages. Unlike RMS, True mode produces even levels across all frequencies. Additionally, True mode will not produce the aliasing or artifacts that RMS detection can cause (a signal-dependent behavior that is true of any RMS-based compressor, not just Neutron).
VU Meters
In Vintage mode, the gain reduction meter uses a VU meter. The decision to use VU or standard Peak metering is down to the user. I love using VU meters at the channel stage as it allows me to visually detect how well the audio is moving along: is it dynamic or not? That needle bouncing up and down is all I need to feel good about the sound. Of course, I am simplifying this serious subject but because I have covered metering and headroom extensively in my video tutorials I feel I can make that remark without a heavy comeback. Again, and as always, determine what you need the metering for and adjust to those requirements.
Side-chain Filter
This allows you to audition the filtered side-chain signal only, so that you may hear the same audio input that’s triggering the compressor. Click the icon to the right of the Side-chain filter (just below the spectrum view) to engage it. I firmly believe that almost all dynamic processors should have a side-chain function. We have moved on from exclusive amplitude detection and need to refine our triggers better and side-chaining allows for that.
Exciter
The Exciter comes next and it really does make an announcement. Offering 4 modes: Retro, Tape, Warm and Tube it sounds lovely but even more interesting is the fact that these modes/topologies can be automated. Morphing the modes has never been easier than grabbing the main control node and dragging it around the modes whilst recording the automation. It doesn’t end there, the Exciter also has a parallel feature. You can blend (dry/wet mix) the dry and wet signals for further colouring.
Pre-Emphasis Modes
These modes allow you to weight the saturation in or away from different areas of the frequency spectrum:
Full offers a gentle, low-mid frequency bump.
Defined offers a gentle, high-mid frequency bump.
Clear offers a gentle, low-mid frequency attenuation.
Post Filter
The high shelf icon overlaid on the spectrum view is a gentle shelving filter capable only of attenuation, to a maximum of -12 dB within a range of 1 kHz to 20 kHz. Drag the filter node to adjust the frequency and gain of the filter, which will be applied to the entire Wet signal, allowing you to further adjust any high frequencies that have been generated by the Exciter module.
I am a fan of Exciters and use them regularly for exciting reverbs, low-end frequencies, vocals and so on. So long as filtering is applied post excitation you will never end up having a brash sound. I wish more people would explore the power of this process.
Transient Shaper
Finally, the Transient Shaper rears its head. Transient Shapers are the new craze. Whereas we used to use amplitude envelopes we now have dedicated transient shapers to further ‘shape’ the sound in a way a simple amplitude envelope cannot. However, if I had to be honest here, Transient Shapers (TS) are glorified envelopes with velocity curve functions. The TS in Neutron Elements offers 3 curve modes: Sharp, Medium and Smooth. That is more than enough to shape a whole channel and deliver the best response.
Gain Adjustment Trace
This view offers a scrolling meter that displays the incoming signal’s waveform with a superimposed curve that illustrates the amount of gain adjustment taking place in real-time.
Paying close attention to the trace juxtaposed over the waveform, and how it illustrates the effect changing envelope modes can have on allowing audio to return to 0 dB of gain before the next transient, is an important tool when seeking to achieve maximum transparency.
Note: the scale can be adjusted on the left-hand side.
The Transient Shaper is more than a glorified envelope. It is actually a potent sound design tool and can be used to create new textures as opposed to simply adjusting the ADSR elements of an envelope.
Metering
Finally, metering. I expect almost all developers nowadays to provide extensive metering options bearing in mind the mediums we have to cater for.
The following, from iZotope’s website, should help to clarify issues:
Meter Type
This allows you to switch Neutron Elements’ metering between a Peak+RMS combo meter and a Peak+Short-term loudness combo meter.
The combined Peak+RMS meter displays a lower bright bar representing the average level (RMS) and a higher dimmer bar representing peak level. There is also a moving line above the bar representing the most recent peak level or peak hold.
Detect True Peaks
By default, the Input/Output meters will only indicate clipping which occurs within the digital domain. To accurately measure the signal that will result from digital to analog conversion, select “Detect True Peaks.”
Spectrum Type
This feature lets you select between four types of spectrums:
Linear: A continuous line connecting the calculated points of the spectrum.
1⁄3 Octave: Splits the spectrum into bars with a width of 1⁄3 of an octave. Although the spectrum is split into discrete bands, this option can provide excellent resolution at lower frequencies.
Critical: Splits the spectrum into bands that correspond to how we hear, or more specifically how we differentiate between sounds of different frequencies. Each band represents sounds that are considered “similar” in frequency.
Full Octave: Splits the spectrum into bars with a width of one full octave.
Average Time
This feature averages the spectrum according to this setting. Higher average times can be useful for viewing the overall tonal balance of a mix, while shorter average times provide a more real-time display.
Show Peak Hold
This shows or hides the peak hold in the audio spectrum behind the EQ. Note this is different from the level meters.
Peak Hold Time
Peak hold time determines how long peaks are displayed after they are detected.
Choices include:
5 ms
250 ms
500 ms
1,000 ms
5,000 ms
Infinite
Conclusion
Ultimately, software is defined by its price versus feature sets and in this department Neutron Elements is a winner.
The feature set is pretty complete giving the user all the necessary tools, from start to finish, to fully optimise the sound/s.
There are alternatives available on the market but none are as simple and elegant as Neutron Elements. My personal favourite for all mastering chores is HarBal but that is a far more detailed and thorough software and although user-friendly it does require a learning curve.
Neutron Elements affords a simple and detailed all-in-one processing solution and is presented with a streamlined and classy GUI that makes it a joy to use. If you can afford the upgrade to Neutron Standard then don’t blink. The extra features are easily worth the upgrade price.
To me, the best recommendation I can give to any product is as follows:
I use it!
https://samplecraze.com/wp-content/uploads/2017/11/neutron-main-1.jpg545800eddiehttps://samplecraze.com/wp-content/uploads/2019/09/samplecraze-logo-red.pngeddie2017-11-03 13:04:522020-01-30 15:23:52iZotope Neutron Elements
Let us start with the sound generation engine of Subtractor.
These are the oscillators.
Subtractor has 2 oscillators. Each one has 32 waveforms but you only need to concern yourself with the basic 4 waveforms as these are your raw waveforms and the balance of the waveforms are simply varying harmonic versions of the main four.
The first waveform is:
Saw waveform, or sawtooths as they are more commonly known, have a rich and bright, edgy sonic quality about them and are great for creating strings, brass, huge Trance pads, searing leads and electro basses. Of course, there is, as with all the other waveforms, far more to it than that, but, as I said, I just want you to get a general idea of what these waveforms are used for and how they sound. The real fun starts when we start to layer them or trigger one with the other, but that will come later when we get into synthesis.
Square waveforms are great for brass and deeper wind type of instruments and are usually used along with other waveforms as they are quite strong and hard on their own. But they are invaluable as are the rest listed above.
Square waveforms look like a bunch of squares with their tops and bottoms missing and alternatively.
Triangle waveforms are great for bell-type sounds or wind type sounds like flutes etc.and I regularly use them for the FM type of sounds that you hear on Yamaha DX7s or FM7s, great and very useful.
These waveforms look like triangles so that makes life easier.
Sine waveforms are great for creating deep warm basses or smooth lead lines. They can be used to create whistles, layered with kick drums to give that deep subby effect. In fact, the sine wave is a pure waveform and the harmonic content is fundamental. That means that almost all other waveforms are created from sine waves.
The sine is a nice smooth flowing waveform.
The rest of the waveforms, from 5-32, are variances on harmonic content and shape structures. This basically means that certain waveforms are created with certain characteristics in mind. For example waveform 11 has been created for designing voice-like sounds, waveform 8 has been created with clav sounds in mind. Each waveform has it’s own attributes and therefore a great starting point for your sound design needs.
OSCs generate waveforms and pitch and these are nicely displayed next to the OSCs in their section. Oct is simply a shift in pitch by octaves either down or up. Semi deals with semitone shifts and this is the standard 12 up or down which makes up one octave. Cents are 100th fractions of the semitones.
Phase
Each oscillator has it’s own Phase knob and a selector button. The Phase knob is used to set the amount of phase offset, and the selector switches between three modes:
Waveform multiplication (x)
Waveform subtraction (-)
No phase offset modulation (o).
When phase offset modulation is activated, the oscillator creates a second waveform of the same shape and offsets it by the amount set with the Phase knob. Depending on the selected mode, Subtractor then either subtracts or multiplies the two waveforms with each other. The resulting waveforms can be used to create new timbres.
Let’s take a simple saw wave example. Offset this slightly and use the subtract mode and you have now created a pulse wave. Pulse waveforms are great for many types of sounds. Again, I suggest you read my synthesis tutorials to listen to and understand how certain waveforms sound and what they can be used for.
But my best advice in this tutorial is to simply play around and attune your ears to the different types of sounds that can be created by simply using the phase functions. We will get deep into this in later tutorials when we come to creating pulse width modulated sounds etc.]
Keyboard Tracking
We now come to osc keyboard tracking. This is an extremely useful little function.
If you deselect keyboard tracking or switch it off, then you will have a constant pitched oscillator. In other words, no matter which note you press, the same pitch is outputted. This is handy when it comes to creating non-pitched sounds like drum and percussive sounds, or special effects, where you do not want the pitch to be evident when you play up or down the keyboard.
Osc mix is the mix for both OSCs. Set it to the left and you only hear OSC 1, set it all the way to the right and you hear OSC 2, set it midway and both OSCs are heard. The OSC 2 output mix is also important because both the ring modulator and noise generator are output through here.
Frequency Modulation
or FM is when the frequency of one oscillator (called the “carrier”) is modulated by the frequency of another oscillator (called the “modulator”). In Subtractor, Osc 1 is the carrier and Osc 2 the modulator.
Using FM can produce a wide range of harmonic and non-harmonic sounds. The best advice I can give, short of a deep and emotional explanation, is to try this function out for yourself. In fact, let’s try a simple example of FM in Subtractor.
To use OSC 2 you need to ‘switch’ it on by clicking on the little box above it. Now select a waveform for OSC 1. Let’s use a saw for OSC 1 and a sine wave for OSC 2. Now set the FM dial to midway and the mix dial to halfway and play away. Sounds nice and metallic huh? You can vary the amounts, change the waveforms etc and later when we come to the mod matrix of Subtractor where we can route sources and destinations, you will find that we can create an endless array of sounds by simply changing what modulates what.
Ring Modulators
basically multiply two audio signals together. The ring modulated output contains added frequencies generated by the sum of, and the difference between, the frequencies of the two signals. In the Subtractor Ring Modulator, Osc 1 is multiplied with Osc 2 to produce sum and difference frequencies.
Ring modulation can be used to create complex and enharmonic sounds. Although this sounds emotional, it’s actually very simple to use.
Let’s try a little ring mod example. Switch on OSC 2 and leave it at the default saw waveform. Now turn the OSC mix dial all the way to the right as the ring mod is outputted on OSC 2. Now switch on the ring mod icon and go to either OSCs semitone tuning section and move the values down a few semitones. You can immediately hear the ring mod sound being outputted.
Cool huh?
We now come to the final part of the OSC section, the noise generator. This can actually be viewed as a third OSC but it does not behave in the same way as the other two as noise is non-pitched.
Noise waveforms
are used more for effect than anything else but I find that they are fantastic for creating pads when used with other waveforms like saws and triangles.
You can also create great seashore wave types of sounds or huge thunder or even some great Hoover type sounds when used with saw waveforms. Hell, you can even create drum and percussive sounds with noise.
Let’s try a little example;
First off, in Subtractor the noise generator is internally routed to OSC 2, so if you switch OSC 2 on then the noise is mixed with the OSC 2 waveform. By switching off OSC 2 and using only osc1 with the OSC mix set all the way to the right, you will only hear the noise generator and not OSC 1 or 2. This sounds complex but is actually quite simple when you practice a little and we will do that right now.
So, use an initialised patch. Move the OSC amt dial all the way to the right. This will bypass OSC 1 ‘s waveform, and because OSC 2 is not switched on, the noise will be heard on its own. Now switch on the noise generator by clicking on the little box above it till it lights up red. You now have noise.
The three parameters are easy to understand and use. Decay is simply how long it takes for the sound to die when you play a note. The less decay the shorter the sound. The more decay you use the longer the sound. It’s actually that simple.
Colour
is a little more involved. If you move the dial all the way to the right, you will get pure or white noise. This comes across as a bright noise sound. Move it back towards the left and the brightness will fade. Move it all the way and you get a low-frequency rumble (great for waves and earthquakes etc). Level is self-explanatory.
Now try the dials. Move the colour all the way to the right. Move the level all the way to the right and move the decay to 1/4 of the way. You will now hear an electro hi-hat. Move the decay to the right on the dial, move the colour to midway and level to midway and you will hear a type of thunder. This is all for now but when we come to modulating this generator you will see that we can create a huge array of different textures.
Filters
A filter is the most important tool for shaping the overall timbre of the sound.
Briefly explained:
A filter allows you to remove unwanted frequencies and also allows you to boost certain frequencies. Which frequencies are removed and which frequencies are left depends on the type of filter you use.
The filter section in Subtractor contains two filters, the first being a multimode filter with five filter types, and the second being a low-pass filter.
Filter Keyboard Track (Kbd)
If Filter Keyboard Track is activated, the filter frequency will increase the further up on the keyboard you play. If a lowpass filter frequency is constant (a Kbd setting of “0”) this can introduce a certain loss of “sparkle” in a sound the higher up the keyboard you play, because the harmonics in the sound are progressively being cut. By using a degree of Filter Keyboard Tracking, this can be compensated for.
Filter 2 A very useful and unusual feature of the Subtractor Synthesizer is the presence of an additional 12dB/Oct lowpass filter. Using two filters together can produce many interesting filter characteristics, that would be impossible to create using a single filter, for example, formant effects.
The parameters are identical to Filter 1, except in that the filter type is fixed, and it does not have filter keyboard tracking.
To activate Filter 2, click the button at the top of the Filter 2 section.
Filter 1 and Filter 2 are connected in series. This means that the output of Filter 1 is routed to Filter 2, but both filters function independently. For example, if Filter 1 was filtering out most of the frequencies, this would leave Filter 2 very little to “work with”. Similarly, if Filter 2 had a filter frequency setting of “0”, all frequencies would be filtered out regardless of the settings of Filter 1.
Filter Link When Link (and Filter 2) is activated, the Filter 1 frequency controls the frequency offset of Filter 2. That is, if you have set different filter frequency values for Filter 1 and 2, changing the Filter 1 frequency will also change the frequency for Filter 2, but keeping the relative offset.
Filter Envelope The Filter Envelope affects the Filter 1 Frequency parameter. By setting up a filter envelope you control how the filter frequency should change over time with the four Filter Envelope parameters, Attack, Decay, Sustain and Release.
Filter Envelope Amount This parameter determines to what degree the filter will be affected by the Filter Envelope. Raising this knob’s value creates more drastic results. The Envelope Amount parameter and the set Filter Frequency are related. If the Filter Freq slider is set to around the middle, this means that the moment you press a key the filter is already halfway open. The set Filter Envelope will then open the filter further from this point. The Filter Envelope Amount setting affects how much further the filter will open.
Filter Envelope Invert If this button is activated, the envelope will be inverted. For example, normally the Decay parameter lowers the filter frequency, but after activating Invert it will instead raise it, by the same amount.
When we talk about distortion the image, invariably, conjured up is that of a guitarist thrashing his guitar with acres of overdrive. However, I am more interested in covering harmonic and non-harmonic distortion in subtle ways using non-linear systems rather than using a specific overdriven effect like guitar distortion or a fuzz box etc.
In an analog system overdriving is achieved by adding a lot of gain to a part of the circuit path. This form of distortion is more commonly related to overdriving a non-linear device. But it doesn’t end there as any form of alteration made to audio being fed into a non-linear device is regarded as distortion even though the term is quite a loose one and not too helpful. The idea is to create harmonic distortion and this is the area I want to explore in this chapter.
Harmonic distortion means that additional harmonics are added to the original harmonics of the audio being fed. As all sound carries harmonic content, and this is what defines its timbre, then it makes sense that any additional harmonics will alter the sound quite dramatically. Harmonic distortion is musically related to the original signal being treated and the sum of the added and original harmonics make up the resultant harmonics. The level and relative amounts of the added harmonics give the sound its character and for this we need to look at the two main types of harmonic distortion: odd and even order harmonics. The exception to this is digital distortion which sounds unpleasant and the reason for this is that the digital distortion is not harmonically related to the original signal.
Harmonics are simply multiples of the fundamental frequency of a sound and the addition of harmonics within a sound defines the sound’ timbre and character. Even order harmonics are even multiples of the source frequency (2, 4, 6, 8 etc) and odd-order harmonics (3, 5, 7, 9 etc) are multiples of the source frequency (fundamental). Even order harmonics (2, 4, 6 etc) tend to sound more musical and therefore more natural and pleasing to the ear and higher levels of this can be used as the ear still recognises the ‘musical’ content. Odd order harmonics tend to sound a little grittier, deeper and richer and higher levels of this cannot be used as abundantly as even-order harmonics as the ear recognises the non-harmonic content and it results in an unpleasant effect. But there are uses for both and depending on how the harmonics are treated some wonderful results can be achieved.
Whenever I have been called into a studio to assist a producer in managing frequencies for pre-mastering I have always been surprised at the fact that people seem to want to attribute a frequency range for the low end of a track. Every track has its own qualities and criteria that need addressing based on the entire frequency content of the track before a range can be attributed to the low end.
I have come across producers affording insights into some interesting low-end frequency ranges and these ranges are relevant only to the context that the track resides in. If we are talking about a heavy Hip Hop track that uses 808 kicks supplemented with sine waves then the low end of that track will vary dramatically to that of a mainstream EDM (electronic dance music) that will incorporate stronger kicks supplemented with ducked bass tones.
So, working on the premise of a frequency range will not help you at all. What is far more important is to understand both the frequencies required for the low end of a specific track and the interaction of these frequencies within themselves and the other elements/frequencies that share this particular range. This might sound strange: ‘within themselves’ but this is the exact area of the physics of mixing and managing low end that we need to explore. When we come to the chapters that pertain to both the harmonic content of a specific frequency range and the manipulation of those frequencies using advanced techniques then all will become clearer.
To fully understand how to manage low-end frequencies we need to look at frequencies, some of the problems encountered with manipulating frequencies, and some of the terminology related to it, in far more detail.
Timbre
We use the term Timbre to describe the tonal characteristics of a sound. It is simply a phrase to distinguish the differences between different sounds and is not reliant on pitch or volume. In other words, two different sounds at the same frequency and amplitude do not signify that they are the same. It is the timbre that distinguishes the tonal differences between the two sounds. This is how we are able to distinguish a violin from a guitar.
Sinusoids
However, to help you in understanding what this has to do with the low end it’s best to explain the first thing about sound, any sound, and that it is made up of sine waves at different frequencies and amplitudes. If you understand this basic concept then you will understand why some sounds are tonal and others are atonal, why a sampled kick drum might exhibit ‘noise’ as opposed to a discernible pitch and why a pure sine wave has no harmonic content.
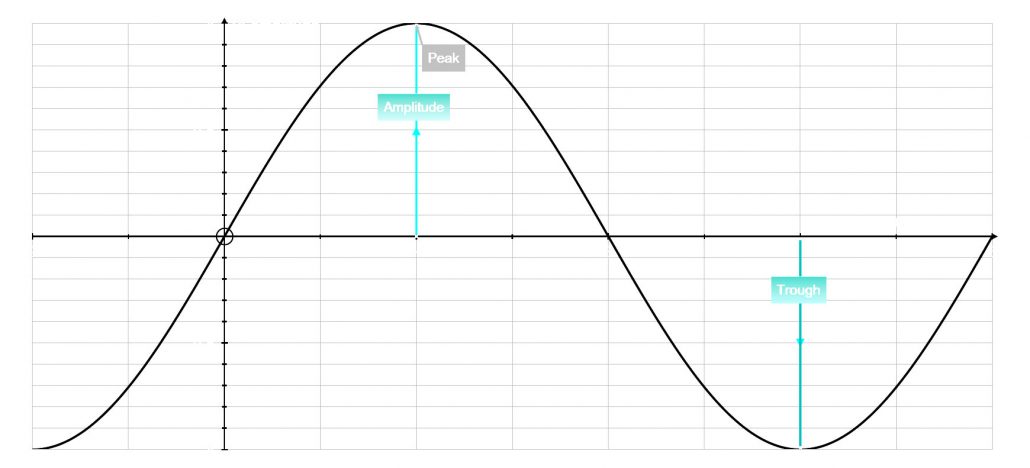
To explain the diagrams below: I have drawn a simple sine wave that starts at 0, rises to +1 which we call the positive, drops to 0 and then drops below 0 to -1 which we call the negative. From 0 to +1 to 0 then to -1 and finally back to 0 is considered one complete cycle.
The phase values are expressed in degrees and lie on the x-axis. A cycle, sometimes referred to as a period, of a sine wave is a total motion across all the phase values.
This cycle is measured in Hertz (Hz) over 1 second and represents frequency. A good example of this is the note A4, which you have come across so many times. A4 is 440 Hz: this means that the waveform cycles 440 times per second (repeats itself) and this frequency represents pitch. If I jump to A5, which is one octave higher, I double the frequency 880 Hz. If I halve the A4 I get A3 (220 Hz) which is one octave lower.
Partial and total phase cancellations are critical to understand as I will be showing you how to use some very specific techniques to create new sonic textures using these concepts. Understanding that a sound has a timbre and that timbre can be expressed by partials which form, apart from the fundamental, both overtones and undertones is equally important as we will cover techniques in managing low frequencies without having to use the fundamental frequency of the sound. Additionally, when we come to managing shared frequencies (bass and drums) then the concept of harmonics is very useful as we are continually fighting the battle of clashing frequencies, frequency smearing, gain summing and so on. For example, sine waves have no harmonic content and therefore some dynamic processes yield no useful results and more specialised techniques are required. Whereas saw waveforms are rich in harmonics and therefore we are able to use pretty standard techniques to accent the sweet spots and eradicate artifacts.
I will now copy the same sine wave and phase offset (phase shift and phase angle) so you can see the phase values:
The shift value is set at 90 which denotes a phase shift of 90 degrees. In essence, the two waveforms are now 90 degrees out of phase.
The next step is to phase shift by 180 deg and this will result in total phase cancellation. The two waveforms together, when played and summed, will produce silence as each peak cancels out each trough.
Summing
When two shared (the same) frequencies (from different layers) of the same gain value are layered you invariably get a gain boost at that particular frequency. This form of summing can be good if intended or it can imbalance a layer and make certain frequencies stand out that were not intended to be prominent. A good way around this problem is to leave ample headroom in each waveform file so that when two or more files are summed they do not exceed the ceiling and clip.
If you take two sine waves of the same frequency and amplitude and sum them one on top of the other you will get a resultant gain value of 6dB.
Summing is important when dealing with the low end as any form of layering will have to take into account summed values.
Masking
When two shared frequencies are layered and one has a higher gain value than the other then it can ‘hide’ or ‘mask’ the lower gain value frequency. How many times have you used a sound that on its own sounds excellent, but gets swallowed up when placed alongside another sound? This happens because the two sounds have very similar frequencies and one is at a higher gain; hence one ‘masks’, or hides, the other sound. This results in the masked sound sounding dull, or just simply unheard. As we are dealing with low end this problem is actually very common because we are layering, in one form or another, similar frequencies.
Partials
The individual sinusoids that collectively form an instrument’s Timbre are called Partials also referred to as Components. Partials contain Frequencies and Amplitudes and, more critically, Time (please refer to my book on the subject of EQ – EQ Uncovered). How we perceive the relationships between all three determines the Timbre of a sound.
Fundamental
The Fundamental is determined by the lowest pitched partial. This can be the root note of a sound or what our ears perceive as the ‘primary pitch’ of a sound (the pitch you hear when a note is struck).
Overtones/Undertones
Using the fundamental as our root note, partials pitched above the fundamental are called overtones and partials pitched beneath the fundamental are called undertones, also referred to as Sub Harmonics. These partials are referred to, collectively, as Harmonics. This can be easily represented with a simple formula using positive integers:
f, 2f, 3f, 4f etc..
f denotes the fundamental and is the first harmonic. 2f is the second harmonic and so on. If we take A4 = 440 Hz then f = 440 Hz (first harmonic and fundamental). The second harmonic (overtone) would be 2 x 440 Hz (2f) = 880 Hz.
Sub Harmonics are represented by the formula: 1/n x f where n is a positive integer. Using the 440 Hz frequency as our example we can deduce the 2nd subharmonic (undertone) to be ½ x 440 Hz = 220 Hz and so on.
An area that can be very confusing is that of harmonics being overtones. They are not. Even-numbered harmonics are odd-numbered overtones and vice versa. The easiest way of looking at this, or rather, counting is to think of it as follows:
Let’s take the A4 440 Hz example: If A4 is the fundamental tone then it is also regarded as the 1st Harmonic. The 1st Overtone would then be the 2nd Harmonic. The 2nd Overtone would be the 3rd Harmonic and so on…
Inharmonic/Inharmonicity
Most musical sounds consist of a series of closely related harmonics that are simple multiples of each other, but some (such as bells and drums for instance) do contain partials at more unusual frequencies, as well as some partials that may initially seem to bear no relation to the fundamental tone, but we can go into more detail about these later on.
It is important to understand this concept as the area of tuning drum sounds and marrying and complimenting the frequencies with tonal basses, is an area that troubles most producers.
When managing low-end frequencies the phase relationships and harmonic content are more important than any other concept because of the limited frequency range we have to process, the nature of the sounds we are dealing with and the types of processing we need to apply.
I have often found frequency charts excellent for ‘normal’ acoustic instruments but a little hit and miss when it comes to synthetic sounds as these sounds will invariably contain a combination of waveforms and associated attributes that will vary dramatically from the standard pre-defined acoustical frequencies. However, ranges of this type can help as a starting point and some of the following might be helpful to you:
Sub Bass
This is the one frequency range that causes most of the problems when mixing low-end elements and for a number of reasons:
We tend to attribute a range starting from (about) 12 Hz to 60 Hz for this vital area. Although our hearing range has a ballpark figure 20 Hz – 20 kHz we can ‘feel’ energies well below 20 Hz. In fact, you can ‘hear’ the same energies by running a sine wave at high amplitude, but I don’t recommend that at all. In fact, we use these sub frequencies at high amplitudes to test audio systems. It is often said that cutting low end frequencies will brighten your mix. Yes, this is true. It is said that too much low-end energy will muffle and muddy up a track. Yes, this is also true. In fact, I cut out any redundant frequencies before I even start to mix a track. However, this is not the only reason we cut certain frequencies below the frequency we are trying to isolate and enhance and it has to do with the impact the lower end of this range has on using processors like compressors (more on this in later chapters).
Bass
I have seen some wild figures for this range as bass can encompass a huge range of frequencies depending on whether it is acoustic or synthetic. But the ‘going rate’ seems to be anywhere between 60 Hz all the way to 300 Hz. The reason this range is so critical is that most sounds, relevant to this low end, in your mix, will carry fundamentals and undertones in this range and will form the ‘boom’ of a track. This frequency range presents us with some of the most common problems that we will try to resolve in later chapters as so many frequencies reside in this range that their summed amplitudes alone will create metering nightmares.
We will deal with frequencies above these ranges when we come to working through the exercises otherwise it is simply a case of me writing another frequency chart and attributing descriptions for each range. I am only concerned with the relevance of these frequencies in relation to the low end and not for anything else.
Kick Drum
I find kick drum frequency ranges almost useless because in today’s music or the genres this book is concerned with, EDM and Urban, kick drums are multi-layered and in most cases samples as opposed to tuned acoustic kicks. So, remarks like ‘boost between 60 Hz – 100 Hz to add low end’, although a guide, is both misleading and unhelpful. We have a general rule in audio engineering/production: you cannot boost frequencies that are not there. Although most sounds will have a sensible frequency range we can use as a guide the kick drum is an entity on its own, simply because of the move away from using only acoustically tuned drum kits to sample-based content. Tonal synthetic kick drums are a different story entirely as the tone will have a pitch but layer that with other drum sounds and they can amass into one big mess if not handled sensibly. The TR 808, through design, behaves tonally but in quite a specific manner thanks to its clever oscillator Bridged T-network, Triggering and Accent.
To help you, purely as a guide, here is a basic chart outlining fundamental and harmonic ranges.
I have included some of the higher frequency ‘instruments’ like the Soprano voice so you can get an idea of the range of frequencies that we have to consider when mixing one frequency range in a track with another. As I said at the start of this chapter, low-end frequency ranges can only be assigned when the entire frequency content of a track is known otherwise it will be a process in isolation and when it comes to mixing that one frequency range with the rest of the track you will encounter problems in ‘fitting it in’.
I have covered the above in most of my eBooks and on my website www.samplecraze.com as part of my ongoing free tutorials. So, if you find the above a little overwhelming please feel free to explore my other books or head on over to my site and read at leisure.
https://samplecraze.com/wp-content/uploads/2017/10/be6ea75921700f8a7d4793313a8325ef.jpg467700eddiehttps://samplecraze.com/wp-content/uploads/2019/09/samplecraze-logo-red.pngeddie2017-10-14 11:13:102020-01-30 15:44:01Low End
What defines a good beat? Well, there is a term we use quite extensively when describing the overall ‘drive’ element of a track: ‘The Nod’. If you can nod to the rhythm of a song, then the beat works. The Nod actually refers to the flow of the beat, and the drive element constitutes the drum beat and bassline together. Because this book is about constructing beats, we will eliminate the bass from the equation. Bass, in itself, is a vast topic that I will cover at a later date when dealing with the low end of a track.
Most producers believe that a well-constructed beat, which has the Nod factor, comes down to two ingredients: the timing information of the whole beat and its constituents, and the dynamics of the individual components. In fact, there is far more to it than that. There are many factors that influence the flow of a drum beat and I will cover the most important ones.
I am Armenian, born in Iran, and have lived in other equally wondrous and safe havens like Lebanon and Kuwait. As a child, I had an obsession with sound, not exclusively music, but sound in its entirety. The diverse cultures to which I was exposed have afforded me the benefit of experiencing some exotic time signatures, dynamics, and timing elements. I always believed that the East held the title for advanced timing variations in music and obscure pattern structures, and for a while this was true. Today, we are blessed with a fusion of cultures and artistic practices. None are more infused with cross-cultural influences as the drum beats we incorporate in modern music.
Let’s break down the different areas that, collectively, form ‘The Nod’.
The Sounds
In dance-based music the choice of drum sounds is critical, and we have come a long way from processing live, acoustic kits into workable sounds that can live alongside a fast and driving BPM (beats per minute). Instead, we use drum samples and, in many cases, layer these samples with other samples and acoustic sounds. In the case of urban music, and the more defined and extreme sub-genre Hip Hop, we tend to go with samples from famous drum modules and drum samplers like the Emu SP1200, Roland TR808/CR78, and the MPC range—most notably the earlier versions such as the MPC60/3000.
The drum samples that we layer and process within a beat must meet very specific requirements. These include topping and tailing, mono/stereo, acoustic/noise/ tonal, and pitch/duration specifications. Let me briefly explain, ahead of the longer discussions later in this book:
Topping and Tailing: This process entails truncating a sample (removing dead space before and after the sample) and then normalising it (using Peak Normalisation to bring the sample’s amplitude/level up to 0dB). We do this for a number of reasons. Crucial considerations include sample triggering, aligning samples on a timeline, and referencing gains within a kit or beat.
Mono/Stereo: A drum sample that displays the same information on both channels is a redundant requirement unless the dual-channel identical information is required when layering using the ‘flip and cancel’ method. (Watch my video Art of Drum Layering Advanced, or read the article I wrote for Sound On Sound magazine entitled ‘Layers of Complexity’ for more information.) The only other instance where a stereo drum sample would be used is if the left and right channel information varies, as would be the case if a stereo effect or dynamic process were applied, or if the sample were recorded live using multi microphones, or if we were encoding/decoding mid/side recordings with figure-8 setups. We try to keep kick samples, in particular, in mono. This is because they remain in the center channel of the beat and, ultimately, the mix. For other samples like snares, claps, and so on, stereo can be very useful because we can then widen and creatively process the sample to taste.
Acoustic/noise/tonal: Acoustic drum sounds will invariably have been tuned at the playing and recording stages but will need to be re-tuned to the key of the track in which the beat lies. Tonal drum samples, like the legendary 808 kick drum, will also have to be tuned. More importantly, the frequency content of the sample will determine what type of dynamic processing can be applied. A sine-wave based tonal kick will have no harmonics within the waveform and will, therefore, be reliant on innovative dynamic processing techniques. Noise-based samples contain little or no tonal information, so require a different form of processing because the frequency content will be mainly atonal.
Pitch and Duration: Ascertaining and tuning atonal drum sounds is a nightmare for many, and this area is covered extensively in later chapters using specific tools and processes. Extending duration with pitch changes, altering pitch without altering duration, using time-stretching, and modulating pitch and/or duration using controllers and automation: all these are excellent forms of pitch manipulation.
Timing
Producers spend more time using the nudge feature and timeline of their DAW, refining timing information for beats, than on other time-variant processes. We have access to so many time-variant tools today that there really is no excuse to be unable to create either a tight and strict beat, or a loose and wandering beat, exactly as required. In fact, we have some nice workarounds and ‘cheats’ for those that have problems with timing issues, and I will cover these in more detail later.
Great timing in beat construction requires understanding several phenomena and techniques that I will explain in this book—BPM and how it relates to realistic timings for ‘played’ rhythms; Quantize, both in terms of divisions and how to alter these divisions; Ghost Notes and how they relate to perception; and Shadowing Beats, including the use of existing loops and beats to underlie, accent, and support the main beat. For example, if your drum beat is too syncopated and has little movement, you can reach for a Groove Quantize template in your DAW, or use other funky tools such as matching slice and hit points to existing commercial breaks.
The perception of a timing variance can be achieved in more than one way. Strangely enough, this leeway has been exhausted to death by Akai with the original Linn-designed pads and contacts. After the MPC 60 and 3000, Akai had no more timing variances in their hardware that could be attributed to ‘the MPC swing and sound’. Far from it. The timing of their DSP is rock solid. The timing of the pad’s initial strike, processed as channel pressure, note on/off and velocity curves, is what adds to the timing ‘delay’. This can be emulated on any pad controller that is sample-based because it is not hardware-specific. To further understand the perceptual formula, we need to look at the sample playback engine of all the top players. Bottom of the list lies Akai with their minimum sample count requirement, which demands so many cycles that if you truncate to a zero point sample start, the unit simply cannot cope with it. Add this ‘dead space’ requirement before a sample can be truthfully triggered to a pad that has inherent latency (deliberately designed by the gifted Roger Linn), and you end up with the ‘late’ and ‘loose’ feel of the MPCs. The sample count issue has now been resolved, and in fact, was corrected from the Akai 2500 onwards. I bring this up so that you are aware that there are very few magic boxes out there that pull out a tight yet loose beat. Nope. They all rely on physics to work. Yet, because of that requirement, we can work around the limitations and actually use them to our advantage. The MPCs have explored and exhausted these limitations quite successfully.
I love using pads to trigger drum sounds as it makes me feel more in touch with the samples than a mouse click or keyboard hit. The idea that drums must be ‘hit’ is not new, and the interaction that exists in the physical aspect of ‘hitting’ drum pads is one that makes the creative writing process far more enjoyable and ‘true’ to its origins. After all, the Maya didn’t have keyboard controllers. For this book, I will be using the QuNeo to trigger samples, but occasionally I will also trigger via the keyboard (Novation SLMK2), because spanning templates can be a little confusing for those that do not understand the manufacturers’ default GM templates.
Early and late processes in aligning beat elements are also a creative and clever workaround for improving static syncopated beats. Simple movements of individual hits using grid subdivisions can add motion to strict 4/4, 3/4 and 6/4 beats, which are the common signatures used in modern music.
Dynamics
Although we think of our brains as really smart organs, they are not actually that smart when it comes to deciphering and processing sight and sound. If you were to snap your fingers in front of your face, the sound would reach your brain via the ears before the visual information reaches your brain via the eyes. That may sound strange because light travels faster than sound, but it isn’t that strange when you take into account the time it takes the brain to decipher the different sensory input. In addition, the brain does not recognise frequency or volume without a reference. This is what memory is for: referencing. The brain has an instinctual response to already referenced frequencies and can turn off like a tap in a hurry when confronted with the same frequencies at the same amplitudes. However, when presented with the same frequencies at varying amplitudes the brain has to work to decipher and reference each new amplitude. This keeps the brain active and therefore interest is maintained. Next time you decide to compress your mix into a square wave because you think it will better ‘carry your mix’ across to listeners by rattling their organs, think twice. A narrow banded dynamic mix simply shuts the brain down, which then goes into ‘irritation mode’ because it has already referenced the constant amplitude for the frequency content in your track. The same processes take place when dealing with drum beats. The most interesting drum beats have acres of dynamic movement and do not rely on a single static amplitude for all the frequencies in the beat. Simple tasks, like altering the individual note velocities or amplitudes, will add huge interest to your beats. I would be surprised if Clyde Stubblefield maintained the same 127 velocity across all his hits whilst playing the drums.
Layering
Individual drum sounds can be layered to give both depth and width, resulting in a texture that can be both dynamic and interesting. If you need to delve into this area in more detail please refer to my book Art of Drum Layering, or the Advanced Drum Layering video which explores very specific layering techniques using phase cancellation, mid/side, and so on. But don’t confine yourself to drum sounds for layering. I have sampled and used kitchen utensil attacks, edited from individual amplitude envelope components, for the attack part of my snares and hi-hats, cardboard boxes close-miked with a large-diaphragm capacitor to capture the boom for kick bodies, and tapping on the head of a directional mic for some deep, breathy samples with which to layer my entire beats, and so on. If you can sample it, hell, use it!
Whole drum loops, treated as layers, can add vibrancy and motion to a static drum beat. Layering loops under a beat not only helps in acting as a guide for those that are not very good at drumming or creating grooves but also allows for some interesting new rhythms that will make the listener think you have incredible insight into beat making.
Layering tones beneath drum beats is an old and trusted method of adding low end. However, simply throwing a sine-wave under a beat doesn’t make it ‘have low-end’. You need to edit the waveform both in terms of frequency (pitch) and dynamics (in this instance: duration and velocity) and take into account the interaction between the low-frequency content of the beat and sine-wave along with the bass line. Many a Prozac has been consumed during the mix-down of this type of scenario.
Modulation
Using modulators to create both motion and texture in a drum beat is not as hard as it may seem at first. The trick, as with all these processes, is to understand the tools and their limitations and advantages. For example, a low-frequency oscillator (LFO) triggering the filter cut-off using a fast ramp waveform shape can add a lovely squelchy effect to a clap sample. Another technique that I have often used is assigning a sine-shaped LFO at a low rate with filter resonance as its destination to run through the entire beat. I then layer this ‘effected’ version with the original dry beat. This gives the perception of tonal changes throughout the beat, even though it is not random.
Drum Replacement/Ripping Beats
Creative beat construction techniques using drum replacement and ripping beats include: substituting your own drum samples for drum sounds within a beat; using the timing information from an existing drum beat as a Quantize or groove template for your own beats; ripping both MIDI and dynamic data from an existing drum beat; and using two beats at different tempos, matching their data to create a new beat that combined drum elements from both beats.
Let’s now look at some of the techniques used to shape and hone drum beats into working ‘Nods’. I will try to incorporate as much of the above as possible into real-life exercises using examples of common chart hits. In terms of tools, I have found that a decent DAW, a capable pad controller, and a good all-round keyboard controller will cover the areas that we require. A pad controller is not crucial, but it does allow for more interaction and dynamic ‘feel’ (we all love to hit pads).
https://samplecraze.com/wp-content/uploads/2017/10/12256884_1069653443054965_461800955_n.jpg480480eddiehttps://samplecraze.com/wp-content/uploads/2019/09/samplecraze-logo-red.pngeddie2017-10-13 09:57:332020-01-30 15:48:24The Nod – How to tell if your track is Banging!
I do not want to get into serious sound reinforcement or acoustic treatment here, for the very simple reason that it is a vast subject and one that is so subjective, that even pros debate it all day, with differing views.
I also believe that every room has it’s own unique problems and must be treated as such, instead of offering a carte blanche solution that would probably make things worse. However, to fully understand what needs to be done to a room to make it more accurate for listening purposes, requires that we understand how sound works in a given space, and how we perceive it within that space.
I think a good place to start, without getting technical, is to think of a room that is completely flat in terms of a flat amplitude response.
This would mean the room has almost no reflective qualities and would invariably be too dead for our purposes. The other side of the coin is a room that is too reflective, and that would be worse than a completely dead room. We need to concentrate on a happy compromise and a realistic scenario.
What we are trying to achieve is to utilize the room’s natural reflective qualities, and find ways to best expose audio, whilst beating the reflective battle.
Whoa, deep statement….
To put it more simply: we are trying to limit the interference of the room with speaker placement and the listening position.
The way we determine the location of sound in a given space is by measuring, with our brains, the delay of the sound between our ears. If the sound reaches the left ear first, then our brain determines that the sound is coming from the left. If there is no delay and the sound arrives at both ears at the same time, then we know that the sound is directly in front of us.
This piece of information is crucial in locating sounds and understanding the space they occupy.
Now, imagine a room that has loads of reflections and reflections that come from different angles, and at different time intervals. You can see why this would provide both confusing and inaccurate data for our brains to analyze.
Sound
Let us have a very brief look at how sound travels, and how we measure its effectiveness.
Sound travels at approximately1130 feet per second.
Now let us take a frequency travel scenario and try to explain it’s movement in a room. For argument’s sake, let’s look at a bass frequency of 60 Hz.
When emitting sound, the speakers will vibrate at a rate of 60 times per second. Each cycle (Hz) means that the speaker cones will extend forward when transmitting the sound, and refract back (rarefaction) when recoiling for the next cycle.
These vibrations create peaks on the forward drive and troughs on the refraction. Each peak and trough equates to one cycle. Imagine 60 of these every second. We can now calculate the wave cycles of this 60 Hz wave.
We know that sound travels at approximately 1130 feet per second, so we can calculate how many wave cycles that is for the 60 Hz wave.
The Calculations
We divide 1130 by 60, and the result is around 19 feet (18.83 if you want to be anal about it). We can now deduce that each wave cycle is 19 feet apart. To calculate each half-cycle, i.e. the distance between the peak and trough, drive and rarefaction, we simply divide by two. We now have a figure of 91/2 feet. However, this is assuming you have no boundaries of any sort in the room, i.e. no walls or ceiling. As we know that to be utter rubbish, we then need to factor in the boundaries. Are you still with me here?
These boundaries will reflect back the sound from the speakers and get mixed with the original source sound. This is not all that happens. The reflected sounds can come from different angles and because of their ‘bouncing’ nature; they could come at a different time to other waves.
And because the reflected sound gets mixed with the source sound, the actual volume of the mixed wave is louder. In certain parts of the room, the reflected sound will amplify because a peak might meet another peak (constructive interference), and in other parts of the room where a peak meets a trough (rarefaction), frequencies are canceled out (destructive interference).
Calculating what happens where is a nightmare.
This is why it is crucial for our ears to hear the sound from the speakers arrive before the reflective sounds. For argument’s sake, I will call this sound ‘primary’ or ‘leading’, and the reflective sound ‘secondary’ or ‘following’. Our brains have the uncanny ability, due to an effect called the Haas effect, of both prioritizing and localizing the primary sound, but only if the secondary sounds are low in amplitude. So, by eliminating as many of the secondary (reflective) sounds as possible, we leave the brain with the primary sound to deal with. This will allow for a more accurate location of the sound, and a better representation of the frequency content.
But is this what we really want?
I ask this because the secondary sound is also important in a ‘real’ space and goes to form the tonality of the sound being heard. Words like rich, tight, full etc. all come from secondary sounds (reflected). So, we don’t want to completely remove them, as this would then give us a clinically dead space. We want to keep certain secondary sounds and only diminish the ones that really interfere with the sound.
Our brains also have the ability to filter or ignore unwanted frequencies.
In the event that the brain is bombarded with too many reflections, it will have a problem localizing the sounds, so it decides to ignore, or suppress, them. The best example of this is when there is a lot of noise about you, like in a room or a bar, and you are trying to have a conversation with someone. The brain can ignore the rest of the noise and focus on ‘hearing’ the conversation you are trying to have.
I am sure you have experienced this in public places, parties, clubs, football matches etc. To carry that over to our real world situation of a home studio, we need to understand that reflective surfaces will create major problems, and the most common of these reflective culprits are walls. However, there is a way of overcoming this, assuming the room is not excessively reflective and is the standard bedroom/living room type of space with carpet and curtains.
We overcome this with clever speaker placement and listening position, and before you go thinking that this is just an idea and not based on any scientific foundation, think again.
The idea is to have the primary sound arrive at our ears before the secondary sound. Walls are the worst culprits, but because we know that sound travels at a given speed, we can make sure that the primary sound will reach our ears before the secondary sound does. By doing this, and with the Haas effect, our brains will prioritize the primary sound and suppress (if at low amplitude) the secondary sound, which will have the desired result, albeit not perfectly.
A room affects the sound of a speaker by the reflections it causes. We have covered this and now we need to delve a little more into what causes these reflections. Some frequencies will be reinforced, others suppressed, thus altering the character of the sound. We know that solid surfaces will reflect and porous surfaces will absorb, but this is all highly reliant on the materials being used. Curtains and carpets will absorb certain frequencies, but not all, so it can sometimes be more damaging than productive. For this, we need to understand the surfaces that exist in the room. In our home studio scenario, we are assuming that a carpet and curtains, plus the odd sofa etc, are all that are in the room. We are not dealing with a steel factory floor studio.
In any listening environment, what we hear is a result of a mixture of both the primary and secondary (reflected) sounds. We know this to be true and our sound field will be a combination of both. In general, the primary sound, from the speakers, is responsible for the image, while the secondary sounds contribute to the tonality of the received sound.
The trick is to place the speaker in a location that will take advantage of the desirable reflections while diminishing the unwanted reflections.
Distance to side wall and back wall.
Most speakers need to be a minimum of a foot or two away from the side and back walls to reduce early reflections. Differences among speakers can also influence positioning, so you must always read the manufacturer’s specifics before starting to position the speakers. A figure-of-eight pattern may be less critical of a nearby side wall, but very critical of the distance to the back wall. The reverse is true for dynamic speakers that exhibit cardioid patterns. In general, the further away from reflective surfaces, the better.
It is also crucial to keep the distances from the back wall and side walls mismatched.
If your speakers are set 3 feet from the back wall, do NOT place them 3 feet from the side walls, place them at a different distance.
Another crucial aspect of the listening position and speaker placement is that the distance from your listening position to each speaker be absolutely identical. It has been calculated that an error of less than ½” can affect the speaker sound imaging, so get this absolutely correct.
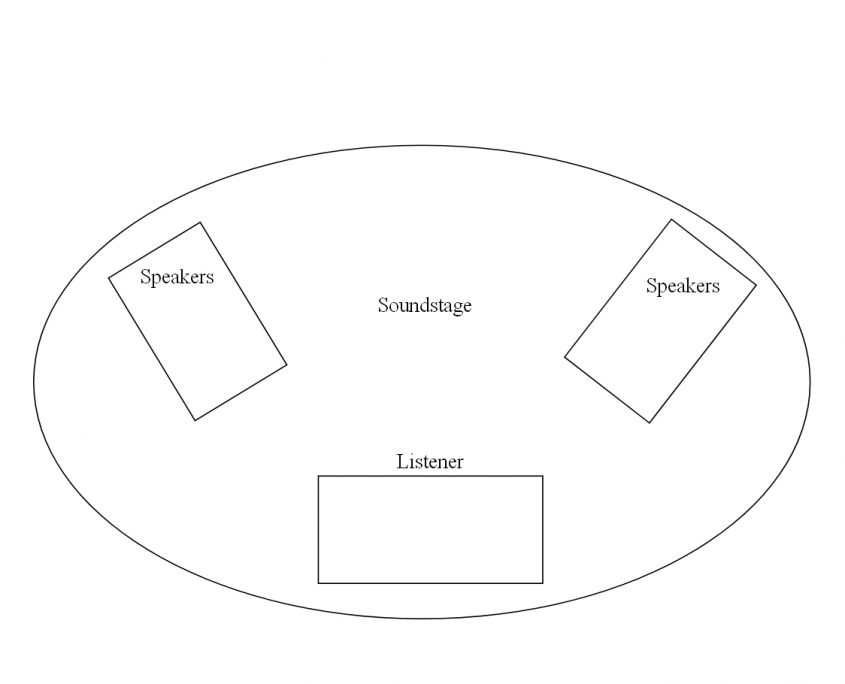
Distance to speakers from listening position.
Once you have established the above, you now need to sort out the distance from the listener to the speakers. I work off an equilateral triangle with the seating position being at the apex of this triangle. The distances must all be equal.
The other factor to consider is the distance between the speakers. Too close and you will get a narrow soundstage with the focus being very central. Widening the distance between the speakers will afford you a wider stereo width, but too far and you will lose the integrity of the soundstage.
Toe-in.
This is the angle of the speakers facing the listener. There are a number of factors that influence the angle of the speakers.
The room, the speakers themselves, and your preferable listening angle. I always start at an excessive toe-in and work outwards until I can hear the soundstage perfectly.
Tilt.
Tilt is also crucial. Depending on the make of the speakers, most speakers are meant to be level set, but some might require tilting and in most cases, the tilt is rear high. If you have to have the speakers tilted then start off level and work from there.
Personally I prefer a level speaker setup.
Listening height.
You will find that the optimum listening height is that of the speaker’s center being at exactly ear height.
However, certain speakers have their own specific height recommendations. You will find that with 3-way systems that incorporate top, mid and subwoofers, the listening height is more customized to account for the woofer placements in the speaker cabin or housing.
Seating location.
I find that keeping the seating position 1-3 feet from the boundary wall gives me the best bass response, and because the distance is too short for the brain to measure the time delay and thus locate the source of the reflection.
Please look at the figure below (Fig 1)
The listening position is at the rear of the room with the speakers facing and forming the equilateral triangle setup, and the listening position forming the apex of the triangle.
The elliptical shape denotes the soundstage and as you can plainly see, the side and rear walls do not interfere with the soundstage.
As you can see, I have created this soundstage using the longer walls as the back and front walls, instead of creating the soundstage with the listening position on the shorter walls. This allows me to position the speakers as wide as is sonically possible and thus affording me a wider stereo field.
Place the listening chair near the rear wall, because the distance (1 to 3 feet) is too short for the brain to measure the time delay and locate the source of the reflection. Also, it places you at the room boundary where the perception of bass is greatest.
Please make sure to take care in optimizing your listening environment.
Once this has been achieved, you can mix far more accurately and truthfully.
https://samplecraze.com/wp-content/uploads/2017/10/Ocean_Way_and_Yamaha_NS-10_Monitors_at_Audio_Mix_House_Studio_B_13430242813.jpg9001351eddiehttps://samplecraze.com/wp-content/uploads/2019/09/samplecraze-logo-red.pngeddie2017-10-12 11:46:322020-01-30 15:54:09Speaker Placement – how to place your studio monitors
I am often asked why I teach my students how to mix to a pink noise profile, be it at the channel stage, or pre-master prepping. The answer is simple: ‘the most important aspect of production is the understanding and management of relative levels.’
When I first began this wonderful and insane journey into audio production I was blessed to have had producer friends that were also my peers. In those ancient days, the industry was very different. The community aspect was both strong and selfless. We were not competing with each other. Instead, we chose to share our knowledge and techniques. It was then that I was introduced to noise as a mixing tool, and coupled with my sound design experience I took to it like a pigeon on a roof.
I was taught the old school method of tuning your ears and mindset to work from a barely audible mix level. If I did not hear everything in the mix then I had to go back and work the quieter channels. If something stood out in the mix then I knew the culprit had to be re-balanced, and all of this relied heavily on relative levels.
Relative levels in a mix context deals with the relationships between all sounds, and that includes effects and dynamics. You may think that relative levels refers only to volume but that is not entirely accurate. Relative levels deals with all level management, from sounds to effects and dynamics. Eq is an excellent example of frequency/gain management, but so are reverb levels, balancing parallel channels or wet/dry mix ratios, and so on……..
An example of how this technique helps the student to understand all areas of relative gains is by throwing in the classic reverb conundrum. We’ve all been there. If there is too much reverb level then the sound will either lose energy through reverb saturation, sound too distant if the wet and dry mix is imbalanced, or sound out of phase. By continual use of this technique, the student learns how well the sound and its effect sit together, whether the dry/wet ratio is right and whether the right reverb algorithms were used. This level of familiarity can only help the student and is the only simple working way of attuning the ears to not only hear level variances but also if something somewhere sounds ‘wrong ‘.
In some ways, this is very much like ear training but for producers as opposed to musicians/singers.
When I feel my students have reached an acceptable level conducting level and pan mixes (another old school apprentice technique), I move them onto pink noise referencing. By the time they have finished countless exercises using all manner of noise responses, they develop an instinctive understanding of gain structuring every aspect of the signal path, from channel to master bus, and with that comes an understanding and familiarity of what sounds natural and ‘right’.
Supplemented with listening to well-produced music this technique has saved my students both time and money and it is such a simple technique that even Trump could do it………well…..with help of course.